How to not use Twitter API to backup & delete your profile
Twitter is really dumb and everyone should delete their accounts. I wrote a different piece on why, so let's just accept that premise. OK, well deleting seems scary because many people have spent years posting on Twitter with tons of original content and photos and whatever. The idea of deleting all of that just to spite Twitter is pretty extreme. But Twitter doesn't own your data—you do! So take it back.
In this post, I'm learning as I go with Twitter API and hope to accomplish the following:
Get access to Twitter APIfuck itUse Twitter API to download all my old tweets and photosjust scrape it- Delete all tweets from my Twitter account
- Bonus: put the content formerly known as tweets on my own web site
So let's get started and see how this unfolds.
How to get access to Twitter API
In order to use Twitter API you must first beg Twitter to grant you access. Currently you have to fill out a "petition" and tell them why you want access, ironically in 200 characters or more. I gave them an honest but intentionally vague description:
I plan to download my own tweets in JSON format. This will enable creating a backup of my content for archival purposes. I will also delete tweets that I no longer wish to publish on Twitter any longer.
Once we go through Twitter's API petition it's time to wait because it looks like there's a human review process and I doubt anyone there is awake at 4am.
UPDATE 12:30pm: I don't need Twitter's permission to access to my own content. They can kiss my ass. I will instead scrape my data right out of their dumb web app. Checkmate, Jack.
How to scrape your posts from Twitter's dumb web app
Alright then, since Twitter's API is stupid, let's just write a scraper to do the same thing. I'm not talking about headless browsers or spoofing requests or anything like that. It should be easy to just write a function to do it right within our browser's JavaScript console.
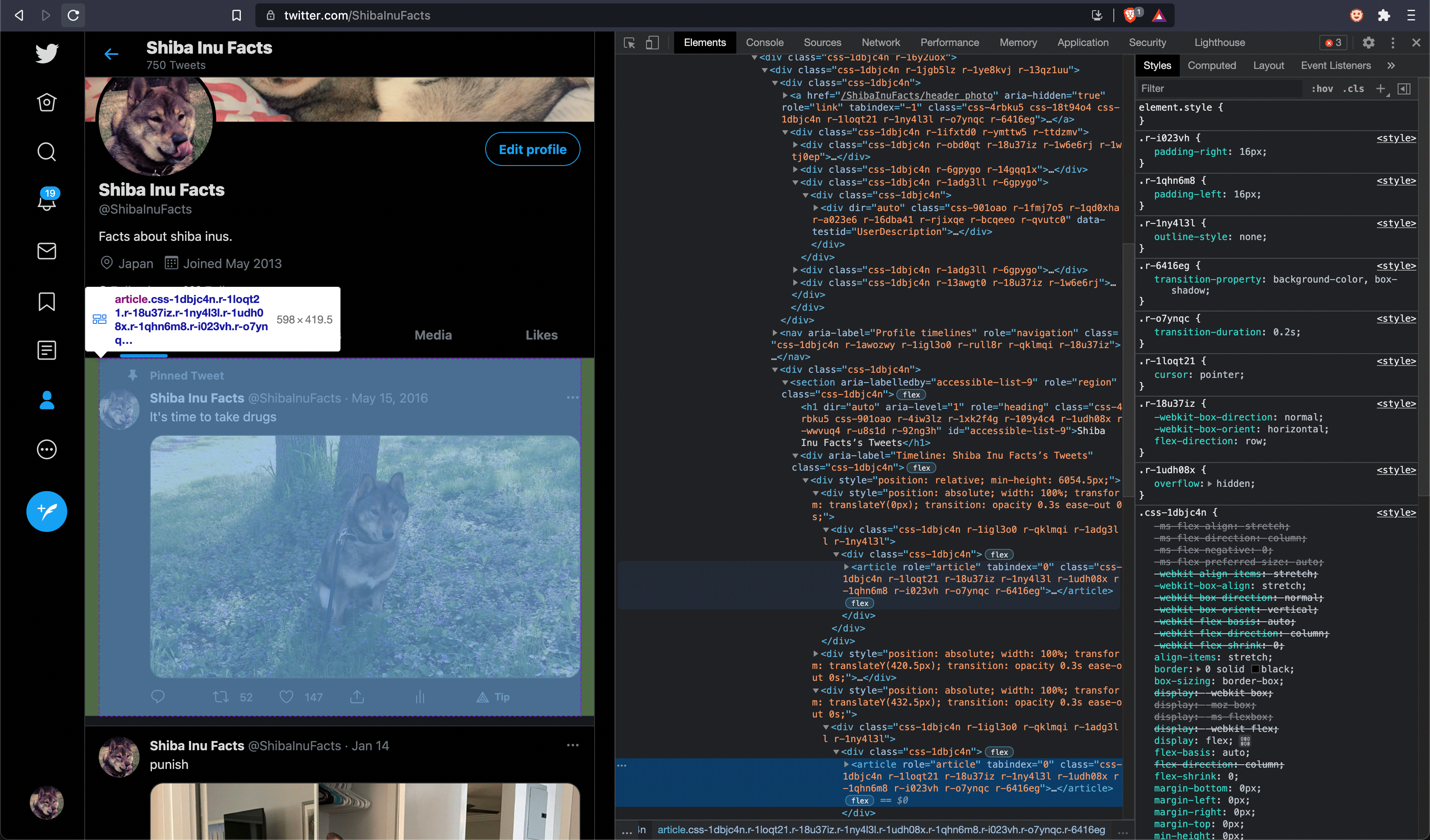
The first step to scraping is to try to isolate the HTML elements that contain
the content you want within the mess of markup that tends to comprise any web
app. With Twitter, it looks like they try to minify and obfuscate their CSS
classes, but that's not really a problem here. After playing around with the
inspector tool in the Elements tab of the browser console, it soon becomes
apparent that all tweets are conveniently contained within <article> HTML
tags.
So now that we've identified where our tweets are located on the page, we can start writing a simple scraper. Switching over to the Console, let's stub out a function to do the work.
let scrape = () => {
let tweets = document.getElementsByTagName('article');
return tweets;
}If you paste that function into the Console on your Twitter profile and then
run it by entering scrape() it should return a bunch of HTML elements that
are hopefully our tweets.
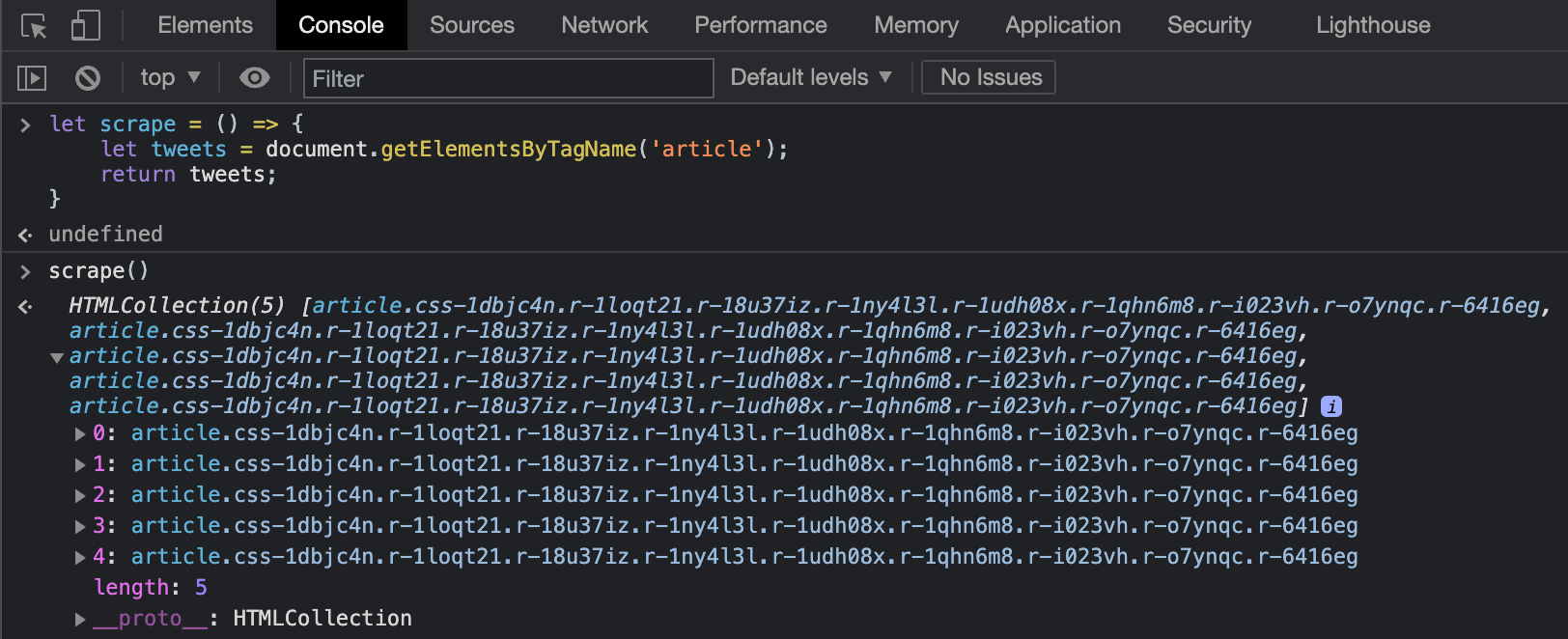
Okay so that worked. After running this, we get a HTMLCollection containing
a bunch of article objects. If you expand open the collection and hover over
any article, you'll see the corresponding tweet highlighted on the page itself.
It's also worth noting that there are only a handful of them - that's because
Twitter only loads a few tweets at a time and you have to "infinite scroll" to
get more of them. But that's okay, we'll get to that later.
So right now we have a proof of concept that finds where our tweets are located on the page, but what we really want is the actual data from each tweet. Stuff like:
- Tweet date
- Any tweet text
- Any images
- Probably other stuff that we'll figure out as we go
Going back to our scraper code, it's time to stub it out a bit further. Now that we've grabbed the tweets, we can scrape the data we need out of each tweet, format the data into structured objects, and build up an array of these objects to scrape the profile into usable "JSON" data. It will start to look a bit like this:
let scrape = () => {
let tweets = document.getElementsByTagName('article'),
json = [];
for (let tweet of tweets) {
let tweetData = {};
// TODO ~ scrape tweet data into properties of the tweetData object
json.push(tweetData);
}
return json;
}If you run scrape() again in this state you'll see it now returns an array
full of empty objects, which is okay. Next we'll get to filling these objects
out with useful information.
Scraping tweet dates
We'll start of with something basic, since tweet dates are just strings
like 'May 16, 2016'. Going back to our Inspector in the Elements tab and
hovering over one of the dates, and we get an easy win. All of the dates are
stored as simple strings inside a <time> tag. And conveniently these tags
all have an attribute storing the post's raw timestamp in UTC format.
So we can get both a "pretty" date string and the actual timestamp with something like this:
// scrape date info
let timeElement = tweet.getElementsByTagName('time')[0];
tweetData.prettyDate = timeElement.textContent;
tweetData.timestamp = timeElement.getAttribute('datetime');If you stick this right under the // TODO comment in the for loop of our
scraper and then run scrape() again, you'll start to see some dates in the
return object! Neato!
Scraping tweet IDs
On Twitter, each tweet has a "numeric" ID that can be used as a reference throughout the API. I put numeric in "quotes" because Twitter's numeric IDs are actually so big that they overflow many generic Integer implementations, or in other words, it's better to actually think of them as strings.
Anyway, since we already scraped the tweet date, getting the ID will be easy.
That's because the timeElement we used previously is contained within a
hyperlink pointing to the tweet itself via a URL containing the tweet's
ID, eg. https://twitter.com/ShibaInuFacts/status/731982565830238209
So all we have to do is grab that hyperlink and slice the ID off the end of its URL:
// scrape tweet ID (place this beneath the 'scrape date info' stuff)
let hyperlink = timeElement.parentNode;
tweetData.id = hyperlink.href.replace(/.*status\//, '');Scraping tweet text
This might be a bit more complicated since tweets can contain rich text, like hashtags and hyperlinks, or whatever. I guess we'll see. Back to the Inspector!
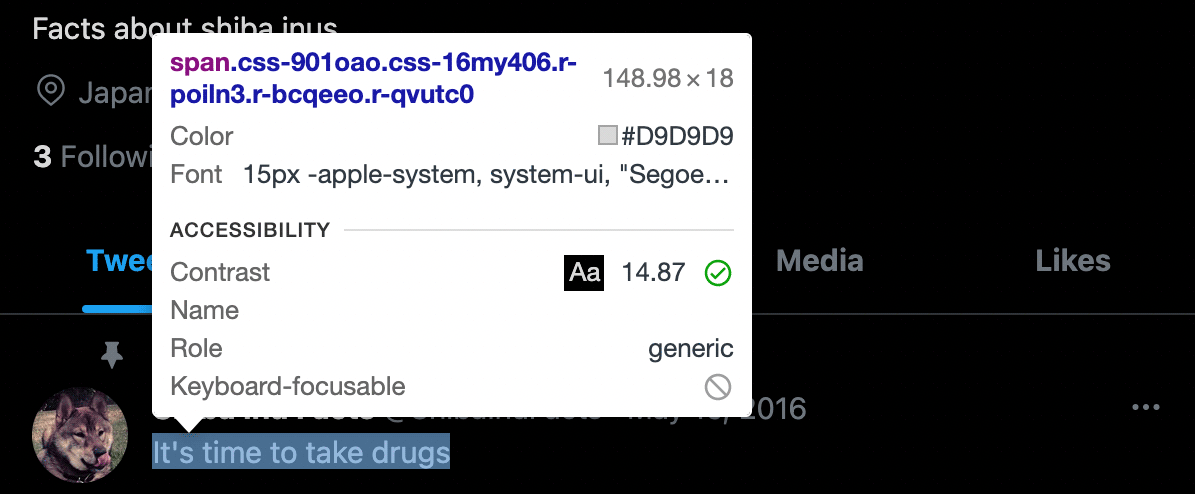
Oh no, that sucks. Twitter stores the tweet text in a <span>
element with css-901oao css-16my406 r-poiln3 r-bcqeeo r-qvutc0 in its CSS
class list. Given that these classes are minified, it's unlikely that this
can be used to programmatically isolate the tweet text itself, at least without
dissecting the minified CSS. We might have better luck looking to the parent
element:
<div lang="en" dir="auto" class="css-901oao r-1fmj7o5 r-1qd0xha r-a023e6 r-16dba41 r-rjixqe r-bcqeeo r-bnwqim r-qvutc0">
<span class="css-901oao css-16my406 r-poiln3 r-bcqeeo r-qvutc0">It's time to take drugs</span>
</div>Alas, the parent element of our useless <span> is almost as annoying. It's
a <div> tag with another list of incomprehensible CSS classes, but a couple
of potential hints we might be able to use to isolate the element. Specifically,
this div has lang and dir="auto" attributes. Perhaps we can isolate on
these attributes to get our tweet text:
// scrape our elusive tweet text
// NOTE THIS IS WRONG! (See the corrected version a little farther down.)
let tweetTextElement = tweet.querySelector('[lang][dir="auto"]');
if (!tweetTextElement) {
console.log('Failed to isolate text in tweet: ', tweet);
continue;
}
tweetData.text = tweetTextElement.textContent;Note that I put a "failsafe" if statement in here in case we can't find any
tweet text—this will console.log out any offending tweet and skip to
the next tweet in the main loop. Scraping is full of assumptions and this
approach will potentially help identify errors in our assumptions.
So plugging this into our scraper function above, and we start to see some useful output:
[
{
"prettyDate": "May 15, 2016",
"timestamp": "2016-05-15T23:00:17.000Z",
"text": "It's time to take drugs"
},
{
"prettyDate": "Jan 14",
"timestamp": "2021-01-15T02:35:33.000Z",
"text": "punish"
},
{
"prettyDate": "Jan 5",
"timestamp": "2021-01-05T22:25:55.000Z",
"text": "Shiba inu decertify the election result"
},
{
"prettyDate": "Jan 5",
"timestamp": "2021-01-05T16:10:30.000Z",
"text": "Covid is a:"
},
{
"prettyDate": "Jan 3",
"timestamp": "2021-01-04T01:45:21.000Z",
"text": "Protip: don’t sit in spiny burrs"
}
]But this can't be so easy. After scrolling farther down the page to load more
tweets and re-running scrape() I start to see some console.logs getting
barfed out from our failsafe. Since we are logging out the actual HTML elements
that are causing problems, I can highlight them on the page by hovering over
them in the console. In one case I see a photo tweet with no text (which should
be allowed but would currently be skipped), but further down I see an
actual error on something a bit more interesting:
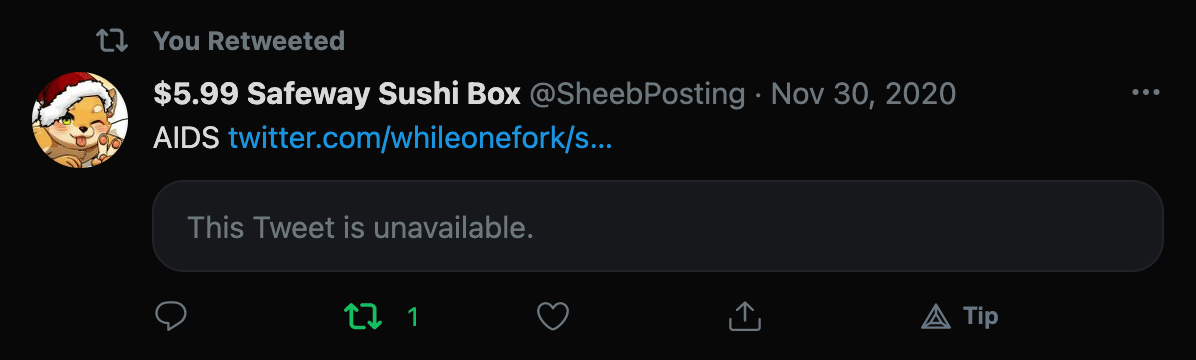
Here we see my retweet of a retweet of a censored tweet. Jack Dorsey strikes
again! There are a couple of problems here. First, I don't want
to get retweets in general since I'm only trying to backup my own tweets. But
that's not actually what's causing the error. Actually, this censored tweet is
causing the scraper to throw an Uncaught TypeError: Cannot read property 'textContent' of undefined.
But that shouldn't be an issue, because the only place we're using textContent
was in the step to get date info, and there's clearly a date on this tweet.
So what went wrong? As usual, the inspector helps here:
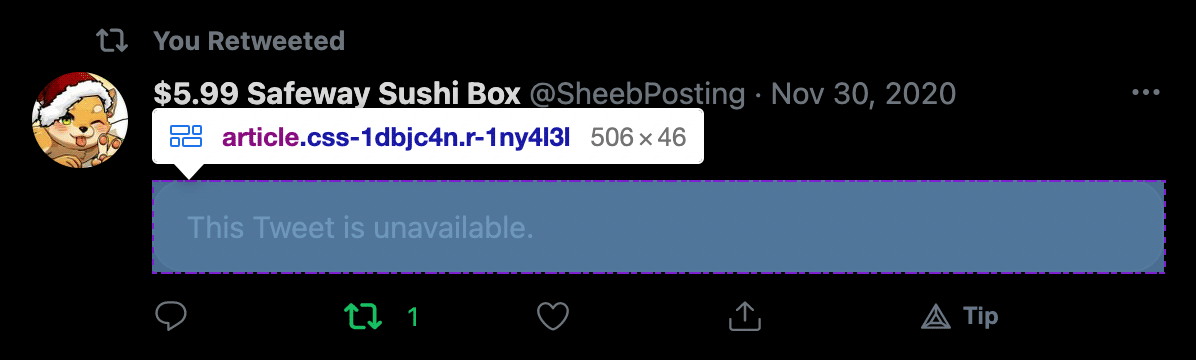
Aha. The issue here is the existence of an <article> tag inside a
nested retweet. Recall that at the beginning we assumed that any <article>
would be a tweet we want to scrape, and that's exactly what our function is
trying to do here. It turns out that all nested retweets use embedded
<article>s and our dumb algorithm will try to scrape all of them as
individual tweets, which is not something we want anyway, but the fact that this
tweet is censored is actually what is causing the algorithm to fail and
alerting us to this issue. We were previously using textContent
in the tweet date scraper—well, this censored tweet is failing specifically
because it has no date. In fact, it's an <article>
with nothing in it but the string "This Tweet is unavailable."
So we'll have to fix this retweet nonsense, but first there's an easier problem to fix. We need to be able to hydrate tweets with no text (eg. a tweet of just a photo or video). That's a simple change to our function:
// scrape our elusive tweet text (corrected lol)
let tweetTextElement = tweet.querySelector('[lang][dir="auto"]');
if (tweetTextElement) {
tweetData.text = tweetTextElement.textContent;
}Here we're just getting rid of the failsafe since it has (hopefully) served
its purpose. From now on, if a tweet has text, we'll add the text to the
tweetData object, and if not, we'll try to get whatever other stuff the tweet
has in it without totally skipping over it.
Filtering out retweets
Again, I don't want to download and store other peoples' tweets, so we need to filter out retweets. There are a couple of facets to this:
- Skip over any straight retweet (where the author is listed as someone else)
- Skip over any quote retweets (where I'm retweeting someone else's tweet with my own comment)
The first one is simple. We can just look at the author of any given tweet and
skip it if it's not our own username (note that I'm using the same
querySelector technique we previously used to isolate the tweet text):
// make sure the tweet was posted by @ShibaInuFacts (aka not a retweet)
let tweetAuthorElement = tweet.querySelector('[dir="ltr"]');
if (!tweetAuthorElement || tweetAuthorElement.textContent != '@ShibaInuFacts') {
console.log('Bad tweet author: ', tweetAuthorElement ? tweetAuthorElement.textContent : '(none)');
continue;
}The second part is a bit trickier. Recall that quote retweets embed a second
<article> tag within the main article for that tweet. What we really want
to do is only look at the top-level articles in the page, but due to how Twitter
obfuscates their CSS classes, this isn't straightforward to do up-front using any
querySelector trick. Instead we'll have to brute force our way through by
checking to make sure any given <article> our scraper looks at isn't nested
inside another one. This can be done by constructing and using a recursive
function:
// make sure this tweet isn't an embedded retweet
const _findParentArticle = node => {
if (!node || !node.tagName) return;
else if (node.tagName.toLowerCase() == 'article') return node;
else return _findParentArticle(node.parentNode);
}
if (_findParentArticle(tweet.parentNode)) {
console.log('Tweet is nested, skipping: ', tweet);
continue;
}Scraping images
Images should be simple, except nothing is simple. Let's take a look:

So images are just stored in an <img> tag. That actually is simple. Since a
tweet may have multiple attached images, we can just grab all images within each
tweet and see what happens:
// scrape images
let images = tweet.getElementsByTagName('img');If we log out the src attribute for all the images in our timeline, we'll get
stuff like:
https://pbs.twimg.com/profile_images/3734166388/e7c4db36f9fff78e8d29741130c2016f_x96.jpeg
https://pbs.twimg.com/media/CiiGPNLUkAEZaWW?format=jpg&name=medium
https://pbs.twimg.com/profile_images/3734166388/e7c4db36f9fff78e8d29741130c2016f_x96.jpeg
https://pbs.twimg.com/media/ErvWNPBXIAAHasX?format=jpg&name=medium
https://pbs.twimg.com/profile_images/3734166388/e7c4db36f9fff78e8d29741130c2016f_x96.jpeg
https://pbs.twimg.com/media/ErAGw21XYAMYPZX?format=jpg&name=medium
...So this is almost perfect. Just a couple of slight problems. Firstly, we keep
seeing repeats of the same profile_images URL, which makes sense because each
tweet shows the avatar image on the left. We'll need to separate this out from
any other attached images. Secondly, the non-avatar images appear to have the
token &name=medium in their URLs. This suggest that these are "lesser," or
smaller, or lower-quality images. We only want the best images! But the
presence of medium suggests that perhaps we could get a large image?
Spoiler alert: it works! Compare the quality of
this medium image to
this large one!
It's a night-and-day improvement. All we have to do is change name=medium to
name=large in the URL.
So with all of this in mind, we write our image scraper as follows:
// scrape images
let images = tweet.getElementsByTagName('img'),
attachedImages = [];
for (let image of images) {
if (image.src.indexOf('profile_image') !== -1) {
tweetData.avatar = image.src;
} else {
attachedImages.push(image.src.replace(/name\=.*/, 'name=large'))
}
}
tweetData.attachedImages = attachedImages;Scraping multiple-choice polls
Twitter lets you run multiple-choice polls on your profile. Is there any hope of scraping these?
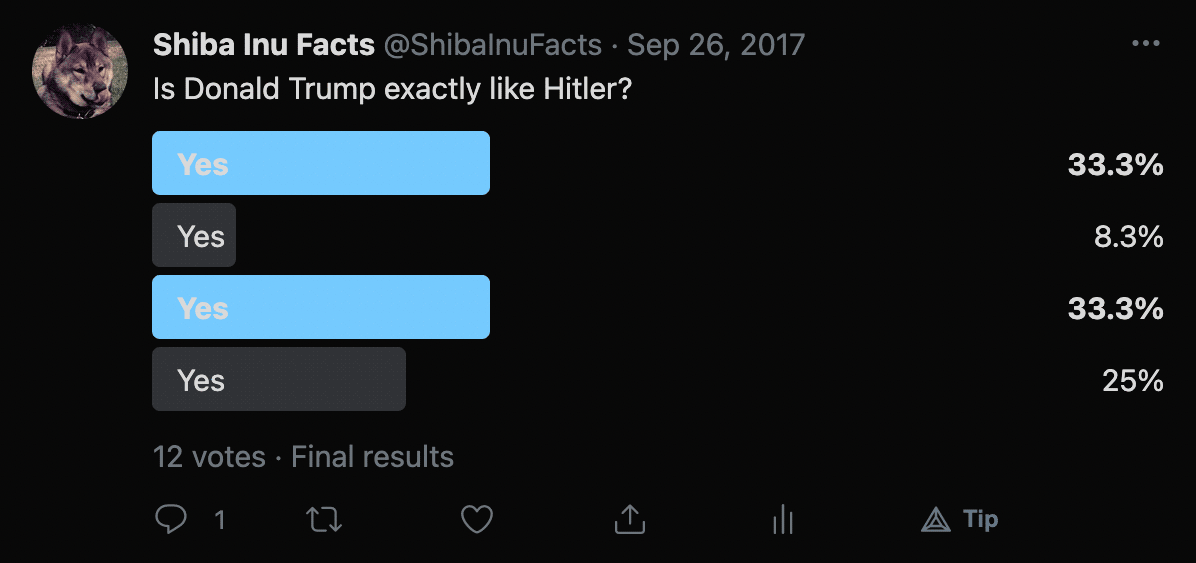
Remember that Twitter minifies all their CSS class names, so this might be a tough one. Let's take a look at the HTML markup for this fine example:
<div class="css-1dbjc4n r-1ny4l3l" data-testid="card.wrapper">
<div class="css-1dbjc4n">
<div class="css-1dbjc4n">
<div class="css-1dbjc4n">
<div class="css-1dbjc4n r-1awozwy r-18u37iz r-mabqd8 r-1wtj0ep">
<div class="css-1dbjc4n r-5dk9ms r-6t5ypu r-z2wwpe r-kicko2 r-1p0dtai r-1d2f490 r-u8s1d r-ipm5af" style="width: 33.3%;"></div>
<div class="css-1dbjc4n r-1e081e0 r-rjfia">
<div dir="auto" class="css-901oao r-1fmj7o5 r-1qd0xha r-a023e6 r-b88u0q r-rjixqe r-bcqeeo r-qvutc0">
<span class="css-901oao css-16my406 r-poiln3 r-bcqeeo r-qvutc0">
<span class="css-901oao css-16my406 r-poiln3 r-bcqeeo r-qvutc0">Yes</span>
</span>
</div>
</div>
<div class="css-1dbjc4n r-f727ji">
<div dir="auto" class="css-901oao r-1fmj7o5 r-1qd0xha r-a023e6 r-b88u0q r-rjixqe r-bcqeeo r-qvutc0">
<span class="css-901oao css-16my406 r-poiln3 r-bcqeeo r-qvutc0">33.3%</span>
</div>
</div>
</div>
</div>
<div class="css-1dbjc4n r-14gqq1x">
<div class="css-1dbjc4n r-1awozwy r-18u37iz r-mabqd8 r-1wtj0ep">
<div class="css-1dbjc4n r-gu4em3 r-6t5ypu r-z2wwpe r-kicko2 r-1p0dtai r-1d2f490 r-u8s1d r-ipm5af" style="width: 8.3%;"></div>
<div class="css-1dbjc4n r-1e081e0 r-rjfia">
<div dir="auto" class="css-901oao r-1fmj7o5 r-1qd0xha r-a023e6 r-16dba41 r-rjixqe r-bcqeeo r-qvutc0">
<span class="css-901oao css-16my406 r-poiln3 r-bcqeeo r-qvutc0">
<span class="css-901oao css-16my406 r-poiln3 r-bcqeeo r-qvutc0">Yes</span>
</span>
</div>
</div>
<div class="css-1dbjc4n r-f727ji">
<div dir="auto" class="css-901oao r-1fmj7o5 r-1qd0xha r-a023e6 r-16dba41 r-rjixqe r-bcqeeo r-qvutc0">
<span class="css-901oao css-16my406 r-poiln3 r-bcqeeo r-qvutc0">8.3%</span>
</div>
</div>
</div>
</div>
<div class="css-1dbjc4n r-14gqq1x">
<div class="css-1dbjc4n r-1awozwy r-18u37iz r-mabqd8 r-1wtj0ep">
<div class="css-1dbjc4n r-5dk9ms r-6t5ypu r-z2wwpe r-kicko2 r-1p0dtai r-1d2f490 r-u8s1d r-ipm5af" style="width: 33.3%;"></div>
<div class="css-1dbjc4n r-1e081e0 r-rjfia">
<div dir="auto" class="css-901oao r-1fmj7o5 r-1qd0xha r-a023e6 r-b88u0q r-rjixqe r-bcqeeo r-qvutc0">
<span class="css-901oao css-16my406 r-poiln3 r-bcqeeo r-qvutc0">
<span class="css-901oao css-16my406 r-poiln3 r-bcqeeo r-qvutc0">Yes</span>
</span>
</div>
</div>
<div class="css-1dbjc4n r-f727ji">
<div dir="auto" class="css-901oao r-1fmj7o5 r-1qd0xha r-a023e6 r-b88u0q r-rjixqe r-bcqeeo r-qvutc0">
<span class="css-901oao css-16my406 r-poiln3 r-bcqeeo r-qvutc0">33.3%</span>
</div>
</div>
</div>
</div>
<div class="css-1dbjc4n r-14gqq1x">
<div class="css-1dbjc4n r-1awozwy r-18u37iz r-mabqd8 r-1wtj0ep">
<div class="css-1dbjc4n r-gu4em3 r-6t5ypu r-z2wwpe r-kicko2 r-1p0dtai r-1d2f490 r-u8s1d r-ipm5af r-1xce0ei"></div>
<div class="css-1dbjc4n r-1e081e0 r-rjfia">
<div dir="auto" class="css-901oao r-1fmj7o5 r-1qd0xha r-a023e6 r-16dba41 r-rjixqe r-bcqeeo r-qvutc0">
<span class="css-901oao css-16my406 r-poiln3 r-bcqeeo r-qvutc0">
<span class="css-901oao css-16my406 r-poiln3 r-bcqeeo r-qvutc0">Yes</span>
</span>
</div>
</div>
<div class="css-1dbjc4n r-f727ji">
<div dir="auto" class="css-901oao r-1fmj7o5 r-1qd0xha r-a023e6 r-16dba41 r-rjixqe r-bcqeeo r-qvutc0">
<span class="css-901oao css-16my406 r-poiln3 r-bcqeeo r-qvutc0">25%</span>
</div>
</div>
</div>
</div>
<div dir="auto" class="css-901oao r-9ilb82 r-1qd0xha r-a023e6 r-16dba41 r-rjixqe r-1s2bzr4 r-bcqeeo r-qvutc0">
<div class="css-1dbjc4n r-1d09ksm r-xoduu5 r-18u37iz r-1wbh5a2">
<span class="css-901oao css-16my406 r-poiln3 r-bcqeeo r-qvutc0">
<span class="css-901oao css-16my406 r-poiln3 r-bcqeeo r-qvutc0">12 votes</span>
</span>
<span aria-hidden="true" class="css-901oao css-16my406 r-9ilb82 r-1q142lx r-poiln3 r-bcqeeo r-s1qlax r-qvutc0">
<span class="css-901oao css-16my406 r-poiln3 r-bcqeeo r-qvutc0">·</span>
</span>
<span class="css-901oao css-16my406 r-poiln3 r-bcqeeo r-qvutc0">
<span class="css-901oao css-16my406 r-poiln3 r-bcqeeo r-qvutc0">Final results</span>
</span>
</div>
</div>
</div>
</div>
</div>After painstakingly tabbing this out, we have what looks like a shit-show, but mainly because the CSS classes are all goofy. Structurally, it actually makes sense. It's a vertical flexbox where each of the flex items except the last is used to render one of the bars in a horizontal bar chart. The last flex item shows some stats about the poll. Unfortunately, the uglified CSS classes make it difficult for our scraper to "grab onto" anything, at least in an elegant fashion. But this can be solved ineligantly!
Starting at the very top, we have div element with data-testid="card.wrapper".
We can use this as a foothold to programmatically target the poll:
// scrape multiple-choice-polls
let pollElement = tweet.querySelector('[data-testid="card.wrapper"]');
if (pollElement && !pollElement.firstChild.ariaHidden) {
// we have a poll! do something...
}Skipping to the part where that definitely works, we've now found our poll and
we want to scrape all the data inside. Thanks to the ugly CSS, we might not be
able to target the individual poll options with querySelectors, but we can
do it the hard way by explicitly walking the DOM from that parent element.
Looking at the aobve HTML again, it's clear that the first child element of our
poll is useless, at least from a markup standpoint. But one node deeper and we
appear to have our vertical flexbox with the poll options plus the one final cell
for the stats. So we can grab it using pollElement.firstChild.firstChild lol.
From here, we want to iterate over each of the options in the poll and grab whatever data we can get, and finally we'll look at the bottom flex item to get the number of votes. At the end we're looking at something like:
// scrape multiple-choice-polls
let pollElement = tweet.querySelector('[data-testid="card.wrapper"]');
if (pollElement && !pollElement.firstChild.ariaHidden) {
let pollFlexbox = pollElement.firstChild.firstChild,
pollData = { options: [], stats: 0 };
for (var i=0; i<pollFlexbox.childNodes.length - 1; i++) {
pollData.options.push({
option: pollFlexbox.childNodes[i].firstChild.childNodes[1].textContent,
percent: parseFloat(pollFlexbox.childNodes[i].firstChild.childNodes[2].textContent.replace('%', ''))
});
}
pollData.stats = pollFlexbox.childNodes[i].firstChild.firstChild.textContent;
tweetData.poll = pollData;
}This is a "good enough" approach. Combined with our tweet text scraper, it will give us scraped objects that look like:
{
"text": "on a scale of 1 to 10, how Asian would you rate shiba inu",
"poll": {
"options": [
{
"option": "1",
"percent": 0
},
{
"option": "2",
"percent": 0
},
{
"option": "3",
"percent": 7.1
},
{
"option": "Asian",
"percent": 92.9
}
],
"stats": "14 votes"
}
}Scraping videos
Here is where we fail. After digging
through Twitter's embedded video player component for awhile with the Inspector,
I found an actual <video> tag buried deep within:
<video
preload="none"
playsinline=""
aria-label="Embedded video"
disablepictureinpicture=""
poster="https://pbs.twimg.com/ext_tw_video_thumb/1340877528496369665/pu/img/V3qUnACSIcZ_BLnc.jpg"
src="blob:https://twitter.com/a306c15f-e055-497d-bead-56a076b25ba6"
...></video>Unfortunately, the src="blob:https://twitter.com/a306c15f-e055..."
leaves our scraper at a dead end. That's because blob URLs aren't normal URLs
that point to a file on some server. Blobs are special URLs that actually point
to a location in the browser's local memory, in this case a MediaSource
object. When combined with server-side streaming software, the
Media Source API
allows the creation very customizable video streaming interfaces in the browser.
And it coincidentally blocks us from getting the video's true URL via
JavaScript, effectively a weak form of DRM.
Luckily I didn't want to download the videos anyway, so I'm glad it doesn't work! Ha! Ha!
Scraping replies, retweets and likes
This one is easy. Using the Inspector, we select the little row at the bottom of a tweet with all of the engagement stats:

Looking to our elements list, we see this is a <div> with aria-label and
role="group" attributes. So we can select on this, and then take
the textContent of the first three children for replies, retweets and likes,
respectively:
// scrape tweet stats (replies, retweets, likes)
let statsElement = tweet.querySelector('[aria-label][role="group"]');
tweetData.replies = statsElement.childNodes[0].textContent || '0';
tweetData.retweets = statsElement.childNodes[1].textContent || '0';
tweetData.likes = statsElement.childNodes[2].textContent || '0';Solving the infinite scroll problem
If you recall from earlier, our scraper only picks up a few tweets when we're
near the top of the page. Again, it's because Twitter only loads in a few
tweets at first and then uses a super-addictive infinite scroll method to load
more tweets as you scroll down. So if you scroll a bit and then re-run our
scrape() function you'll start to see more tweets getting picked up.
Now you might think "No problem! I'll just scroll to the bottom to load all the tweets in and then run the scraper!" Yes, this would be a great idea, except it doesn't work. The problem is that as you scroll further down the page, Twitter's app actually removes the higher-up tweets from the page HTML. And then if you scroll up, it quickly loads back in those higher tweets and discards the lower ones. Effectively Twitter's React App is using a memory-management trick to prevent a theoretically infinite amount of tweets from occupying an infinite amount of page memory. Clever, but it also makes our job harder, since at any given time there are only a handful of tweets actually rendered on the page that our scraper can access.
This is annoying but not insurmountable. It can probably be solved with an algorithm like this:
scrape()- Try to scroll the page a little bit. If we hit the bottom then skip to 4.
scrape()again, ignoring duplicates. Goto 2.- We're done lol
There are a couple of things that need to change in our scrape algorithm to
support this behavior. First, since we originally designed this to be a one-shot
algorithm, the json array of scraped tweets is created and scoped within the
scraper function itself and is inaccessible from the outside. We will need to
define our json array outside of the scrape function and use the function to
build the array up (but not create it).
The second change is tracking and ignoring duplicates. Since we will be running
scrape() multiple times as the page scrolls down, it's likely that at any
given point there will be tweets loaded in that we've already scraped. So we
need to track if any given tweet is one we've already scraped, and, if so,
ignore it. This can be accomplished with a dictionary object that we can define
outside of our scraper and reference from within it.
So all-and-all, we're looking at a few structural changes to the scraper:
let json = [],
duplicateDictionary = {};
let scrape = () => {
let tweets = document.getElementsByTagName('article');
for (let tweet of tweets) {
let tweetData = {};
// ...
// ... skipping a bit until we grab our tweet ID
// ...
tweetData.id = hyperlink.href.replace(/.*status\//, '');
// now, check for and skip duplicates
if (duplicateDictionary[tweetData.id]) {
continue;
}
// ...
// ... skipping to the bottom
// ...
json.push(tweetData);
// add this tweet to our duplicate dictionary
duplicateDictionary[tweetData.id] = true;
}
return json;
}Basically, whenever we scrape a tweet, we also add the tweet's ID into the
duplicateDictionary. Then, if we scroll down, scrape again and the same tweet
is still loaded on the page, we will find its ID in the dictionary and skip over
it, allowing only unique tweets to be added to our json array.
UPDATE 8:40am the next day: Twitter granted my API application! Oh well, they can still kiss my ass.
Anyway, after tweaking the scrape algorithm, we're now able to continually
build up our json array, grabbing more and more tweets as we scroll the page
and manually call scrape(). Now we just need a function to automate this
scrolly-scrapey behavior.
And here it is! Our new scrollAndScrape function combined with all the other
stuff we've pieced together so far:
let scrollAndScrape = async () => {
// async helper function to wait some number of milliseconds
const _wait = ms => new Promise(resolve => setTimeout(() => resolve(), ms));
// scrape whatever tweets are currently on the page
scrape();
// scroll a little bit down from where we are
window.scrollTo(0, window.scrollY+((document.body.scrollHeight - window.scrollY)/3));
// wait a sec for react to render any new tweets
await _wait(1000);
// scrape whatever tweets react just streamed in
scrape();
// scroll all the way to the bottom
window.scrollTo(0, document.body.scrollHeight);
// wait a split second for the loading indicator to have time to appear
await _wait(50);
let progressBar = document.querySelector('div[role="progressbar"]');
// if no loading indicator then we're done
if (!progressBar) {
return console.log('SCRAPING COMPLETE: ', json);
}
// otherwise wait for the loading indicator to disappear
let moreTweetsLoaded = false;
while (moreTweetsLoaded == false) {
let checkProgressBarAgain = document.querySelector('div[role="progressbar"]');
if (!checkProgressBarAgain) {
moreTweetsLoaded = true;
} else {
await _wait(100);
}
}
// wait a second to not overwhelm twitter with requests
await _wait(1000);
console.log('... scraped ' + json.length + ' tweets');
// DO IT AGAIN
scrollAndScrape();
}
let json = [],
duplicateDictionary = {};
let scrape = () => {
let tweets = document.getElementsByTagName('article');
for (let tweet of tweets) {
let tweetData = {};
// make sure the tweet was posted by @ShibaInuFacts (aka not a retweet)
let tweetAuthorElement = tweet.querySelector('[dir="ltr"]');
if (!tweetAuthorElement || tweetAuthorElement.textContent != '@ShibaInuFacts') {
console.log('Bad tweet author: ', tweetAuthorElement ? tweetAuthorElement.textContent : '(none)');
continue;
}
// make sure this tweet isn't an embedded retweet
const _findParentArticle = node => {
if (!node || !node.tagName) return;
else if (node.tagName.toLowerCase() == 'article') return node;
else return _findParentArticle(node.parentNode);
}
if (_findParentArticle(tweet.parentNode)) {
console.log('Tweet is nested: ', tweet);
continue;
}
// scrape date info
let timeElement = tweet.getElementsByTagName('time')[0];
tweetData.prettyDate = timeElement.textContent;
tweetData.timestamp = timeElement.getAttribute('datetime');
// scrape tweet ID (place this beneath the 'scrape date info' stuff)
let hyperlink = timeElement.parentNode;
tweetData.id = hyperlink.href.replace(/.*status\//, '');
// now, check for and skip duplicates
if (duplicateDictionary[tweetData.id]) {
continue;
}
// scrape our elusive tweet text (corrected lol)
let tweetTextElement = tweet.querySelector('[lang][dir="auto"]');
if (tweetTextElement) {
tweetData.text = tweetTextElement.textContent;
}
// scrape images
let images = tweet.getElementsByTagName('img'),
attachedImages = [];
for (let image of images) {
if (image.src.indexOf('profile_image') !== -1) {
tweetData.avatar = image.src;
} else {
attachedImages.push(image.src.replace(/name\=.*/, 'name=large'))
}
}
tweetData.attachedImages = attachedImages;
// scrape multiple-choice-polls
let pollElement = tweet.querySelector('[data-testid="card.wrapper"]');
if (pollElement && !pollElement.firstChild.ariaHidden) {
let pollFlexbox = pollElement.firstChild.firstChild,
pollData = { options: [], stats: 0 };
for (var i=0; i<pollFlexbox.childNodes.length - 1; i++) {
pollData.options.push({
option: pollFlexbox.childNodes[i].firstChild.childNodes[1].textContent,
percent: parseFloat(pollFlexbox.childNodes[i].firstChild.childNodes[2].textContent.replace('%', ''))
});
}
pollData.stats = pollFlexbox.childNodes[i].firstChild.firstChild.textContent;
tweetData.poll = pollData;
}
// scrape tweet stats (replies, retweets, likes)
let statsElement = tweet.querySelector('[aria-label][role="group"]');
tweetData.replies = statsElement.childNodes[0].textContent || '0';
tweetData.retweets = statsElement.childNodes[1].textContent || '0';
tweetData.likes = statsElement.childNodes[2].textContent || '0';
json.push(tweetData);
// add this tweet to our duplicate dictionary
duplicateDictionary[tweetData.id] = true;
}
return json;
}If you paste all of this into your browser console on your Twitter profile and
run scrollAndScrape(), you can watch the magic happen! The code will page
down through your timeline, scraping as it goes, and at the end it logs out
an array full of your very own hydrated tweets! No dumb oAuth API required!
You can now copy this array into the editor of your choice, and congratulations—you've got JSON!
How to mass-download all your tweet photos from Twitter's CDN
Now that we've converted our whole timeline into JSON, we have one problem to solve before we nuke all our tweets. See, the photo URLs in our JSON point to Twitter's CDN, and if we delete the tweets those photos will be deleted too. To solve this, we'll mass-download our own photos from Twitter!
I'm sick of looking at JavaScript, so let's write a python script to download
everything. Assuming you have python3 installed, you can start off a new image
downloader project like so:
henriquez@punishy python3_projects % mkdir image_downloader
henriquez@punishy python3_projects % cd image_downloader
henriquez@punishy image_downloader % mkdir imagesNow create a download.py file in your image_downloader project folder and
plop your timeline JSON into a variable called tweets:
import urllib.request
import time
tweets = [
{
"prettyDate": "May 15, 2016",
"timestamp": "2016-05-15T23:00:17.000Z",
"id": "731982565830238209",
"text": "It's time to take drugs",
"avatar": "https://pbs.twimg.com/profile_images/3734166388/e7c4db36f9fff78e8d29741130c2016f_x96.jpeg",
"attachedImages": [
"https://pbs.twimg.com/media/CiiGPNLUkAEZaWW?format=jpg&name=large"
],
"replies": "0",
"retweets": "52",
"likes": "147"
},
# .... truncated for readability
]
for tweet in tweets:
if len(tweet['attachedImages']):
for i, image in enumerate(tweet['attachedImages']):
print('Downloading %s...' % image)
destination = './images/%s_%d.jpg' % (tweet['id'], i)
urllib.request.urlretrieve(image, destination)
print(' - saved: %s' % destination)
time.sleep(0.5)
print('done lol')
Now if you run python3 download.py you'll see your tweets downloading into
the images folder!
How to delete all your tweets with one weird trick
At this point we have everything we need from Twitter: a JSON dump of our whole timeline and a backup of all of the photos we've ever uploaded. It's time to delete.
Once again we can easily do this by hacking the browser console. First, using the Inspector, we find the hamburger button that opens the context menu on any given tweet:

It's a <div> with attributes role="button" and aria-haspopup="menu". Easy.
Next, we actually open the menu and find the Delete option:

It's a <div> with role="menuitem" and the word "Delete" as its
textContent. Easy again! Now we click through to the delete confirmation
dialog and find the big red button:
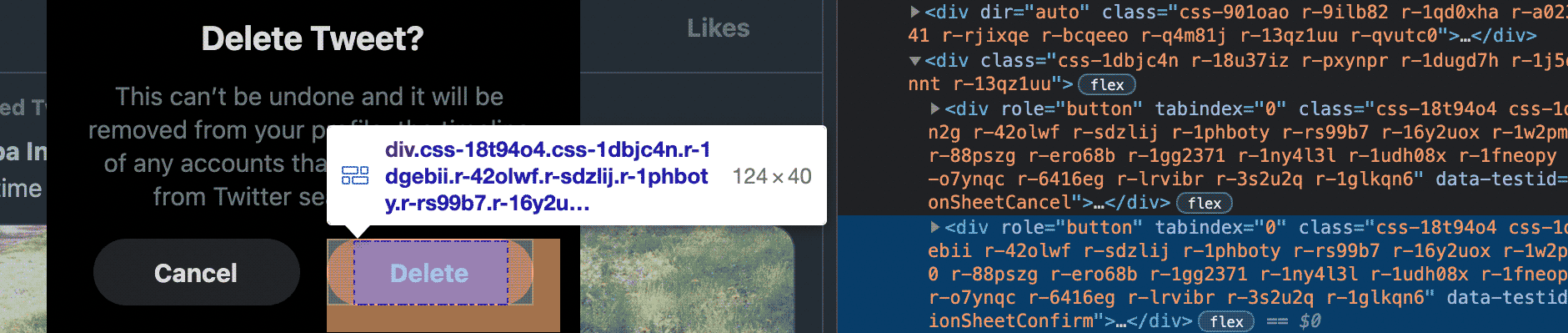
It's a <div> with data-testid="confirmationSheetConfirm". Now we have all
the pieces we need to build a script to programmatically click through all of
these steps on each of our tweets:
let massDelete = async bypassConfirmationPrompt => {
if (!bypassConfirmationPrompt) {
if (!confirm('Are you sure you wish to delete all your tweets? This is permanent.'))
return;
if (!confirm('No, seriously. This is not a joke. DO YOU WANT TO DELETE ALL YOUR TWEETS?'))
return;
}
// async helper function to wait some number of milliseconds
const _wait = ms => new Promise(resolve => setTimeout(() => resolve(), ms));
// helper to close any popup dialog
const _closeDialog = async () => {
document.querySelector('div[role="dialog"]').firstChild.click()
await _wait(50);
}
// grab the next tweet, or if none left then we're done
let tweet = document.querySelector('article');
if (!tweet) {
console.log('R.I.P.');
return;
}
// scroll to the tweet in the timeline so the dialog doesn't glitch out
let inView = false;
while (inView == false) {
let coords = tweet.getBoundingClientRect(),
offset = 1;
if (coords.top < 0) offset = -1;
else if (coords.top < 100) inView = true;
window.scrollTo(0, window.scrollY+offset);
}
// click the tweet context menu
let contextMenu = tweet.querySelector('[role="button"][aria-haspopup="menu"]');
contextMenu.click();
await _wait(500);
// load the context menu options
let menuOptions = document.body.querySelector('[role="menuitem"]').parentNode,
deleteOption = null;
// try to find a delete option in the context menu
for (var i=0; i<menuOptions.childNodes.length; i++) {
if (menuOptions.childNodes[i].textContent == 'Delete') {
deleteOption = menuOptions.childNodes[i];
}
}
// if no delete option exists then this is likely a retweet, let's undo it.
if (!deleteOption) {
_closeDialog()
let statsElement = tweet.querySelector('[aria-label][role="group"]'),
retweetButton = statsElement.querySelector('[aria-haspopup="menu"]');
retweetButton.click();
await _wait(250);
let unretweetConfirm = document.querySelector('[data-testid="unretweetConfirm"]');
if (unretweetConfirm) {
unretweetConfirm.click()
// or it might be part of a thread that we don't care about. skip it.
} else {
_closeDialog()
tweet.parentNode.removeChild(tweet);
}
// else delete the tweet
} else {
deleteOption.click();
await _wait(500);
let confirmButton = document.body.querySelector('[data-testid="confirmationSheetConfirm"]');
confirmButton.click();
}
await _wait(250);
massDelete(true); // pete and repeat were sitting on a fence
}Paste this into your browser console and then enter massDelete(). The code
gives you a final chance to change your mind. Choose to proceed and witness each
tweet on your timeline being banished to the Shadow Realm! They didn't
stand a ghost of a chance!

BONUS: Reincarnate your content on your own website!
Now that all your tweets are deleted and Jack Dorsey is crying in between bong rips, it's time to give them a new life on your independent website. NOTE: once your tweets are off Twitter's platform, we aren't allowed to call them tweets anymore. That's because Twitter trademarked the word "tweet"!

So the first step is to figure out what to actually call these bits of content now that they're out of Twitter's control. I will leave that decision to you, dear reader. Actually, it's all up to you from here! This is getting long enough without me explaining how to make a web site. Check MDN for great tutorials.
* See the new and improved Shiba Inu Facts *
FUN FACT! Twitter supposedly actually allows you to export a .zip of your profile data from your settings screen, so it could be argued that this was all pointless! But I would argue shut up.