first
- Reply
- (hidden)
In the 25 years since JavaScript was first added to Netscape Navigator, the language has evolved from a cute little toy to an integral part of the Internet. JavaScript frameworks such as React and Angular have transformed the web, bringing us fully-fledged client side applications with functionality that could only be imagined just a decade ago. In the process, the web has become more powerful, but also much more dangerous. Malware and mass surveillance have become persistent threats, fueled by the ever-expanding amounts of user data exposed by new JavaScript features, and sucked into the black hole of omnipresent tracking networks. With real human costs, these threats have been worsened by the increasingly popular belief that "the web browser is an operating system, and everything is an app."
This essay is written for web developers and people interested in the field. In it, I break down the problems mentioned above, demonstrate some commonly-used JavaScript practices that can expose users to harm, provide examples of actual harm being done, and ultimately propose some actionable alternatives that we, as developers, can adopt to prioritize ethical engineering and minimize harm for our users, while still building feature rich applications.
In the early days of the web, JavaScript was only available in a handful of web browsers, each with their own special way of doing things. Because browser support was so inconsistent, JavaScript was unreliable and mostly used as a way to add non-essential flair to web pages, which were generally static or rendered server side.
Eventually Netscape and Internet Explorer emerged as dominant browsers for the early 2000's, but their inconsistencies extended far beyond JavaScript. In order to tame that beast, there was a major push within the engineering community to create web standards and make web browsers behave more predictably. As existing features were standardized and new features were added, a problem arose: how do we deliver new features to the web while ensuring good user experiences on older software or less-powerful hardware? The solution was proposed as the concept of "progressive enhancement":
By adopting a progressive enhancement approach, developers could take advantage of newer features while still writing code that would work across a wide range of browsers. This was an absolute necessity throughout the mid-to-late 2000's, as Internet Explorer remained dominant as a ubiquitous but garbage-tier browser. Monolithic JavaScript toolboxes like jQuery and MooTools were created to work around browser quirks and allow developers to reliably use JavaScript on their sites, but single page apps were still impossible, and the biggest sites all used server-side rendering, treating JavaScript mostly as an optional enhancement.
Everything changed in the early 2010's with the ascendency of Google's Chrome browser. Google marketed their browser aggressively and users quickly abandoned Internet Explorer, and with them developers. Finally, between Firefox and Chrome, we had two popular standards-compliant browsers that could carry the web forward. Internet Explorer support quickly dropped out of the web development metagame, and support for the browser among developers went from mandatory to being seen as a painful chore, and a barometer on whether any particular employer had long-term tech vision.
With the fall of Internet Explorer and the mass adoption of standards-compliant web browsers, we could for the first time rely on consistent behavior. The least common denominator had been raised, significantly. Visions of the web that had been held back for years by Microsoft's awful browser could finally be attained, and the web developer community became drunk with power. Single page apps rose in popularity as quickly as the client side frameworks that enabled them; jQuery and MooTools became increasingly irrelevant as DOM manipulation was now reliable via native APIs; browser vendors raced to implement new web standards and APIs as fast as they could be created. The last decade has certainly been an exciting time to be a web developer!
Unfortunately, in the midst of all this excitement, the mindset of progressive enhancement has fallen by the wayside. The notion of the World Wide Web as a collection of pages enhanced by CSS and JavaScript is now widely seen as antiquated. Because our least common denominator in terms of reliable functionality has increased so much, our fundamental relationship with the web as a medium has shifted towards taking this increased functionality for granted. Web sites that only work with JavaScript enabled are now common, even on largely "static" sites like blogs. In fact, "web site" is no longer a reliable default descriptor for any given web property. Progressive enhancement has been supplanted by the idea that "the web browser is an operating system, and everything is an app."
Imagine an operating system where all software development must be done in QBasic; it's an operating system that downloads, installs and executes any program the moment it is encountered, without your permission, and it leaks information about your activities to anyone who wants to spy on you. No it's not Windows 10; you've basically imagined a modern web browser.
JavaScript is a toy programming language.
Like QBasic, JavaScript was never designed for serious use. It has deeply ingrained quirks and bugs which can never be fixed without breaking the millions of scripts that have made peace with the existence of those bugs and depend upon the well-known workarounds. Standards like "strict mode," ECMAScript 2015 and transpiled languages like TypeScript can only graft on top of JavaScript's fundamental problems in an attempt to control the chaos.
Browsers were not designed to be operating systems.
Web browsers were originally designed to display web pages. While Mozilla, Google, and (somewhat) Apple have done a great job extending the functionality of their browsers to meet the demands of fully client side JavaScript-driven apps and APIs, their efforts are the product of decades of prolonged scope creep driven by developer demand. This has led to a sense of confused identity, not just for the browsers, but for the browser vendors themselves. Failed initiatives like Firefox OS and Chrome OS (be honest) are examples of this confusion, that awkward space between the web browser being a purpose-built tool and a fully-qualified operating system capable of driving the hardware upon which it resides.
Mozilla and Google found out the expensive way that their browsers are not great as operating systems. It turns out that, despite peoples' hopes and dreams to the contrary, browsers aren't particularly good app execution environments. Again, be honest with yourself: when was the last time you saw a web app with performance or capability similar to a native app compiled for the platform it's running on? We've been promised this ideal since Progressive Web Apps became a thing, but in practice it has rarely panned out. The closest I've seen are apps like Slack or Postman running on the Electron framework, but they tend to be slow and buggy (though to be fair they do work.)
You probably don't need to build an "app."
Consider this: in the 16 years that this blog has existed in one form or another, we've seen generational advances in computing hardware that have put orders of magnitude more performance into the hands of consumers. Today we have mid-range cell phones that blow my 2004 development PC away in terms of CPU, graphics, memory and storage speed. And yet, the perceived performance I've experienced using the web on better hardware throughout the years has not increased, and in many cases is worse. I doubt I'm alone in experiencing this. So what happened?
Let's ignore the explosion of ad tech, and look to two basic examples: Gmail and Twitter. Gmail used to be fast, and now it's slow and bloated. On my fiber connection, it takes nearly two seconds to render anything beyond a loading animation (generally a bad sign) and several more seconds to fully stream in content for various sections of the page. Why so slow? A quick trip to the Network tab in the browser console reveals that more than 4.6 megabytes of JavaScript are needed just for the list of emails to first render. After that point, 8 more megabytes of JavaScript stream in and various elements on the page render asynchronously. All this while, a further 3.5 megabytes of XHR data are transferred across more than 60 separate API calls. Google tries to hide how slow all of this is using deferred rendering tricks, but clicking on any UI element while all this data is flying back and forth reveals the real UI slowdown caused by all these reflows and data transfers.
Twitter is a similar (though less tragic) story. Their new React app is a fraction of the size of Gmail, but it still uses a fullscreen loading animation and deferred rendering ticks to hide the weight of over 3 megabytes of JavaScript and 1 megabyte of XHR for the initial load. But what sucks is their React app just feels slower than the previous version, which used a combination of server side rendering with client side JavaScript enhancements. Twitter used to be fast (when you weren't seeing the Fail Whale.)
Neither Gmail nor Twitter's web apps come close to the smoothness of their native clients. And their recent migrations to fully client side progressive web apps are a step backward in terms of perceived UI performance. So what was the point? We got type safe transpiled code, UI frameworks that abstract basic rendering capabilities away from what HTML and CSS could give us for free, and libraries within libraries. We saved Google and Twitter money by moving the work of actually rendering the page away from the server and onto the client. All of this required treating the web browser like an operating system through the mandatory use of JavaScript, and it's debatable how much of any of it benefited the end user.
I'm not arguing that you shouldn't write client side apps. What you should do depends entirely on your use case. But more often than not there are better alternatives to building fully client side apps (which I'll get to), and requiring users to enable JavaScript in order to benefit from your work exposes them to potential harm.
The fundamental security model of JavaScript on the web is based upon the faulty assumption that it's safe to execute arbitrary code on web pages because that code is sandboxed within the browser and unable to access a user's private data from the filesystem or execute programs in the operating system at large. While this assumption may have been safe in the 1990's when JavaScript was little more than a toy, it has not held up as browsers have approached the functionality of operating systems in and of themselves and browser vendors have raced to implement new JavaScript standards without proper consideration to user privacy or security implications. As a result, more and more private data leaks out of the browser with every cool new JavaScript API that gets added. The totality of this data is sufficient to precisely track and deanonymize users, which fuels annoying adtech at best and life-or-death consequences at worst.
While security-conscious individuals would often prefer to disable JavaScript by default, the recent abandoment of progressive enhancement design principles by web developers has left more and more of the modern web walled off to users who choose to not run scripts for their own security or safety. And for everyone else, JavaScript has become a black hole that sucks in ever more data through omnipresent third-party origin scripts. Nobody knows where this data is going, least of all the developers who plug these scripts into their sites.
In order to deliver new features, browser vendors are in an arms-race to adopt and implement new web standards, oftentimes before those standards are fully baked. This has lead to the release of JavaScript APIs with glaring security holes that later have to be patched out, but only after they've been widely exploited by bad actors.
Example 1: WebRTC IP address leakage
WebRTC is the peer-to-peer realtime communications standard that enables voice and video calls in web browsers; popular examples include Slack and Google Hangouts. This was released in browsers as far back as 2012, well before the standard was considered stable (which wasn't until 2018).
As a result of being rushed to market before it was ready, WebRTC released with a security flaw that leaked users' IP addresses - both at the ISP and LAN level, and this leakage would pierce VPNs. This enabled a trivial JavaScript attack that was widely used by shady actors to harvest users' true IP addresses, even when those users were taking steps to protect their privacy.
Because the flaw stemmed from a fundamental problem in WebRTC's peer negotiation API, it could not be fixed without breaking WebRTC itself and all the apps that used it. It took many years for a proper workaround to be standardized, and browsers only deployed the fix very recently with the release of Chrome 76 in August 2019, and Firefox 74 last month.
In some jurisdictions and situations, IP addresses are considered Personally Identifiable Information (PII) and are protected under privacy regulations like GDPR and CCPA. Mishandling of PII can expose a website operator to significant liability. But beyond the potential legal ramifications, the WebRTC situation was just a breach of trust and a bad look for browser vendors.
(To test if your browser is leaking your true IP address, check out ipleak.net or the proof-of-concept attack on Daniel Roesler's Github.)
Example 2: Web MIDI API dumps a list of connected USB devices
You might be surprised to learn that a JavaScript MIDI API even exists. But it's true—you can connect a MIDI Keyboard to your computer and use it in music apps powered by JavaScript in your web browser.
A year ago I was playing around with the MIDI API in Chrome while working on
a software synthesizer, when
I noticed a pretty serious problem:
Chrome's implementation of the API carelessly skipped over the user agent
permission prompt, which is part of the spec.
Instead, Chrome would immediately dump a list of connected USB MIDI devices,
with no user notice or consent, whenever a call to requestMIDIAccess was made.
When I first wrote about this, I noted that the leakage of USB devices could be used to deanonymize users, but didn't believe this was widely known or used by any bad actors. However, last week I was doing some "security research" with a more recent build of Chromium, which has fixed the permission problem, and I ran into this prompt on popular porn site xhamster.com:
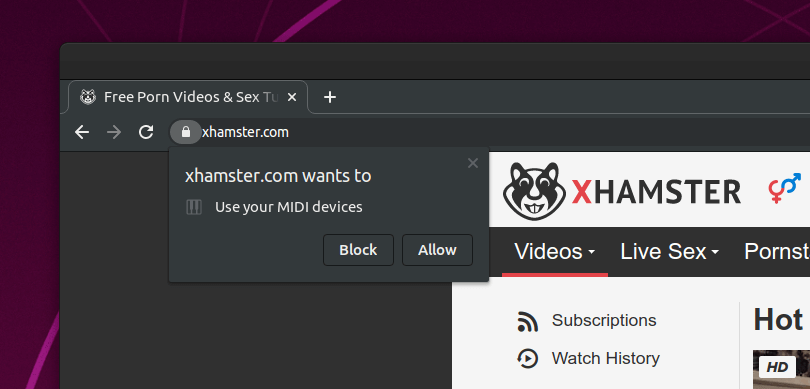
So for users not running the latest releases of Chrome, xhamster.com is not blocked by this prompt and able to silently invoke a JavaScript API that can dump a list of connected USB devices. God knows what xhamster wants with that, or any of the numerous other JavaScript APIs they are calling in "interesting" ways, one of which involves a very sketchy PDF file. (I've collected collected a lot of information on them, which will be a fun post for another day.)
But getting back to the point, there's no reason a JavaScript MIDI API even needs to exist, much less needs to exist so urgently that Google had any justification to half-ass the implementation and skip over a permission prompt, exposing Chrome users' USB data to shady porn networks.
It's a common misconception that JavaScript exposes only non-identifying information and thus any tracking done with that information is "anonymous." In reality, the sheer number of data points JavaScript leaks about the user's browser, OS, graphics hardware, screen size, system drivers, and network enables precise fingerprinting of the user's hardware, with sufficient accuracy for tracking cookies to be "revived" even after being cleared by the user. From here, all it takes is a leakage or disclosure of first-party identifiers to a context where a tracker can pick them up, and a user's real-world identity can be deanonymized and persistently monitored across the web.
The Electronic Frontier Foundation (EFF) has a great write-up and demonstration of device fingerprinting techniques via their Panopticlick Project:
When you visit a website, you are allowing that site to access a lot of information about your computer's configuration. Combined, this information can create a kind of fingerprint — a signature that could be used to identify you and your computer. Some companies use this technology to try to identify individual computers.
While Mozilla has attempted to mitigate some common fingerprinting techniques with Firefox's Enhanced Tracking Protection, much of their approach relies on blacklists (aka "whack-a-mole"). For Chrome, Google has business incentives as the world's biggest advertiser to not give a shit about fingerprinting, as the techniques are primarly used by shady adtech players (aka their competition), and thus strengthen Google's lobbying position as "one of the good guys" that they leverage to widen the regulatory moat around their Better Ads coalition, maintaining their dominance over the entire industry.
The most reliable way to resist fingerprinting is to disable JavaScript, which is why the privacy-focused Tor Browser bundles NoScript by default.
If all of this comes off as unhinged paranoia, please keep in mind that many human rights activists use the Internet and are frequent targets for both domestic and foreign government surveillance, and worse. During my time at a nonprofit civil rights advocacy group in the U.S., one of my colleagues kept getting interesting malware on her Macbook laptops. She swore she was security-conscious enough to not be downloading and installing random executibles from the Internet. I was initially skeptical, but after issuing her a new Macbook and seeing it compromised again in short order, I suspected she was being hit by a JavaScript-based drive-by attack staged from some shady ad network. If true, this would likely have been a targeted attack, as it wouldn't make sense to risk burning a valuable zero-day vulnerability by mass-spamming it. Due to the potential for undetectable firmware-level malware on Macs, we had to retire these infected computers to a pile on my shelf.
Later, around the time of the 2016 election, my executive director got this notice from Google while logging into his Gmail account (we were told it was Russians):
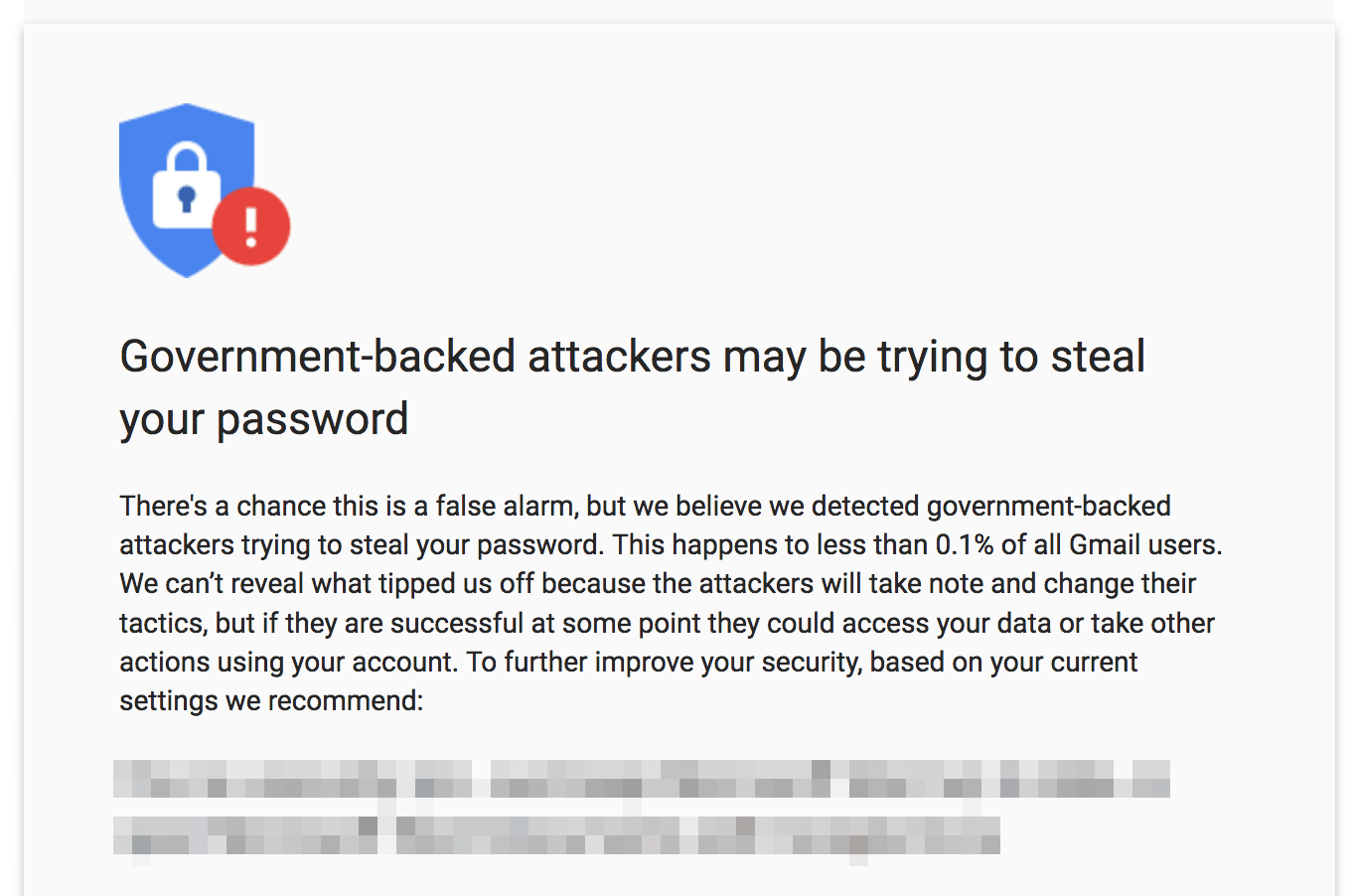
Here in the U.S., where we have laws and civil rights, malware and phishing attacks are mostly just annoying. It's never fun to have your data stolen and it's expensive to keep buying new laptops every time someone gets infected. But in countries like Iran or China, where civil rights are suppressed and activists frequently "disappear," these types of targeted attacks can have life-or-death consequences. In Edward Snowden's disclosures of National Security Agency surveillance practices, he revealed that the NSA piggybacks off U.S. ad networks to precisely target individuals. It's a fair bet that hostile foreign governments are doing the same sort of thing with less-savory foreign ad networks. This is why human rights workers must take care to protect themselves from trackers, scripts and browser fingerprinting.
But beyond government-based attacks on activists, ordinary users are also frequent victims of malware infections propagated via malicious JavaScript techniques.
Another example: Grandma gets pwned
A few years back, my elderly mother-in-law clicked a promoted article on her msn.com homepage and fell prey to an India tech support scam. Spread via ad network Taboola, which failed to properly vet their advertisers, the scam site used various JavaScript techniques to render an unclosable fullscreen popup. A dire warning flashed on her screen—a harmful virus was deleting her files! But a beacon of hope appeared: "Call Microsoft Support," urged the fake Windows dialog box. It was only after sending $200 worth of iTunes gift cards to the helpful support technicians, who had guided her through the process of installing a remote access tool on her machine, that she realized maybe something wasn't quite right. By the time she thought to call her family tech support guru, it was too late.
While grandma might not be savvy enough to disable JavaScript, episodes like this highlight the risks that webmasters subject their users to when they embed third-party tracking and content recommendation scripts on their sites.
By this point it might seem like I've written a "JavaScript considered harmful" essay, but that's not the case! JavaScript is a tool, and like any tool it can be used for harm. It's our ethical responsibility as developers to choose to use JavaScript, and all other tools at our disposal, to write code that minimizes harm and respects peoples' human rights.
Remember — users are human beings and privacy is a human right.
So how do we respect peoples' human rights with our code? In the case of privacy, it boils down to respecting peoples' privacy preferences. If a person is sending the Do Not Track header, we do not track them. If they have JavaScript disabled, we treat this as a privacy preference and do our best to serve them with other tools we have available—good old-fashioned server side rendering, HTML and CSS. In other words we re-adopt a progressive enhancement mentality when designing our code, and treat client side JavaScript as optional, when possible.
Obviously, this won't always be possible. If you're writing a video conferencing app using WebRTC, or a music app using the Web MIDI API, these would simply not work with JavaScript disabled. But to the extent these were features in a larger project, they could be delineated as "JavaScript required" features, while other functionality would still be supported with JavaScript disabled.
While we can always write code that respects peoples' privacy preferences, it's worth noting that we can only minimize the potential for harm. Whenever we write code or people execute it, there is always a basic assumption of risk on both sides:
These risks are inherent to all software and should not block us from releasing our work. However the question of "should this software even exist?" and other ethical considerations are relevant and covered in the next section.
Again, ethical engineering is using the tools at our disposal to write code that minimizes harm and respects peoples' human rights. I've painted with some broad strokes above, but now focus on some actionable steps that any web developer can take to apply an ethical mindset to their work. This is not an exhaustive list, and I invite you to share your own ideas in the comments below.
1. Respect the Do Not Track (DNT) header.
If a person's browser is passing the DNT header, do not place any cookies without their explicit permission. Explicit permission would be logging into your site by previding credentials, oauth or similar; or alternatively, the person could opt-in to cookies by clicking a link or submitting a form indicating their permission.
If a person has opted-in to cookies, pass a Tk: C response header as described
in section 6.2 of the
W3C Tracking Preference Expression draft.
You may also wish to create a
Do Not Track Policy in accordance with the
EFF's well known format. Doing so will inform other software that your domain
respects peoples' tracking preferences.
2. Consider making JavaScript optional with Isomorphic Design.
With Isomorphic Design, your site can be rendered both server side and client side, making it possible to offer a single-page application (SPA) to people who enable JavaScript while gracefully degrading to a server side-rendered set of pages for people who disable JavaScript.
Isomorphic Design allows you to treat JavaScript as both a progressive enhancement and a privacy preference. Popular frameworks including React and Meteor support Isometric JavaScript.
If you can't deliver certain features without client side JavaScript (for example a socket-based chat), but your app could otherwise be isomorphic, consider delineating these features as "JavaScript required" instead of requiring JavaScript for your entire app. Explaining the benefits of enabling JavaScript in specific contexts empowers people to make informed choices while respecting their privacy.
3. Avoid the use of third-party scripts, trackers, and analytics.
Embedding code from origins you do not control presents a couple of problems:
The third party may harvest peoples' data in ways that harm their privacy. This may include tracking them across the web or disclosure to third parties. This is the "black hole" effect of JavaScript on the web—when you embed third party scripts, you may as well put a giant asterisk on your own privacy policy, because you have no actual control over what these third parties are doing with peoples' data.
Embedding remote scripts allows the remote origins full control over the JavaScript functionality on your own site. Typically we expect third parties to "behave," but there is no guarantee that the third party will not be compromised or otherwise act maliciously. In extreme cases, a third party script could activate keyloggers, harvest login credentials, download malware, etc.
For site analytics, consider using Matomo as a locally-hosted alternative to Google Analytics.
4. If you must embed a remote script, enable Subresource Integrity (SRI).
Subresource Integrity
is a security feature that enables browsers to verify that resources they
fetch (for example, from a
CDN) are delivered
without unexpected manipulation. It allows you to include a
cryptographic hash
with any remote <script> tag, which the browser verifies on load. If the
script does not match its SRI hash, the browser blocks it.
Subresource Integrity is a great way of keeping honest origins honest. It is a safeguard against a remote origin being compromised or otherwise behaving maliciously, because a script will just be blocked if they try any funny business.
5. Learn about and defend against common security threats.
The web is a dangerous place. As developers we have a responsibility to act with a basic level of competence to protect the security of our software and the people who use it. While no one can anticipate every possible security threat, everyone can learn the basic threats that face many sites and are widely exploited across the web. These low-hanging fruits include Cross-Site Scripting (XSS), SQL Injection, and Cross-Site Request Forgery (CSRF). MDN has a great write-up on Website security which could be considered required reading for a beginner.
6. Use HTTPS!
HTTPS encrypts all traffic to and from your server. This prevents all flavors of malicious actors from intercepting and monitoring peoples' data in transit. HTTPS used to be an expensive hassle to set up, but now it's free and easy thanks to the Let's Encrypt project. It's [current year] — use HTTPS!
7. Implement a Content Security Policy (CSP).
Content Security Policy is an added layer of security that helps to detect and mitigate certain types of attacks, including Cross Site Scripting, and data injection attacks.
Using a CSP is especially important if your site allows people to post content (for example a commenting system). Typically you would attempt to sanitize user-generated content (UGC) and prevent people from embedding remote scripts on your site, but you might not be able to forsee all the "creative" ways malicious individuals could try to get around your best efforts. With CSP, you can block any scripts being loaded on your page from all but a pre-approved set of origins, among many other benefits. This gives you a good layer of defense against many common attacks.
8. Consider releasing under a Free / Libre license.
Taking the previous steps will help protect peoples' right to Privacy. Software can also protect other human rights, including the right to Free Speech.
Free Speech is often a flashpoint for controversy on the web, largely due to the platform effect of centralized social media and discussion platforms. In order to protect the goals of any sufficiently large platform that hosts user-generated content, it becomes necessary to moderate (aka censor) speech. This applies to the largest social media sites and the smallest discussion forums. For example, if you're running a gardening forum, you may not wish to allow discussions that devolve into presidential politics; it is simply not relevant to your purpose in offering the site.
By releasing your code as Free / Libre Software, using the GNU General Public License or similar, you grant people four freedoms:
You may not wish to allow certain types of speech on your own servers, but by releasing Free Software, people have the freedom to run your software on their own servers for their own purposes. This protects peoples' freedom of speech, among the other freedoms enshrined by your Free / Libre license. It also helps in the efforts to re-decentralize the Internet. Look to the Mastodon Project as an example of decentralized Free Software that protects Free Speech.
9. Try to minimize harm; consider whether your software should even exist.
All too often, engineers release software not because it's a particularly good idea, but simply because they can. To be an ethical engineer, it's crucial to weigh the benefits your software poses to the people who use it against the forseeable harm your software could do, both to the same people and to society at large. Only you and your personal ethics can determine where the tipping point is, where the benefits may be outweighed by the forseeable harm. But if you could consider your own software harmful, it is worth holding back and rethinking your approach.
If you want to learn more about ethics in tech, I'd highly recommend the following resources: